Performance testing through proportional traces
TL;DR: This article describes a novel system-independent approach to performance testing using tracing
As software becomes pervasive in our lives, more people rely on it to perform increasingly more complex tasks. Either because of impaired user experience or real-time constraints, software performance tends to eventually become as important as software correctness. As a response to these problems, we accumulated decades worth of methodologies, tools and heuristics to detect, analyze and fix software performance problems.
However, once a performance problem is addressed, the problem morphs into an equally interesting one: how do we ensure the performance problem remains fixed?
Approaches to performance testing
Typical approaches to performance testing fall into one of the following categories.
Outlier detection using historical data
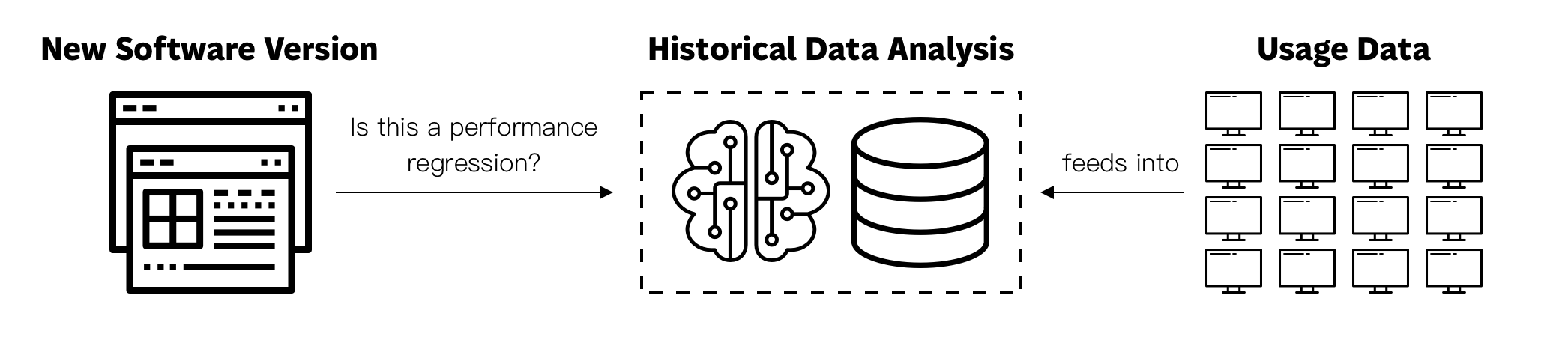
This methodology consists in collecting performance data and comparing the current performance against historical data. This data usually comes from end-users or other type of production systems. The comparison process is often complex and involves data normalization, outlier detection algorithms and machine-learning.
For example, producers of a desktop application, like Postman, can collect telemetry about the time it takes for the application to open on a large number of devices across operating systems, architectures and system configurations. If the desktop application starts in under 1 second for 95% of users, a patch causing the desktop app to start in over 2 seconds for 90% of users is likely to be flagged as an outlier for further investigation.
A/B testing against other versions
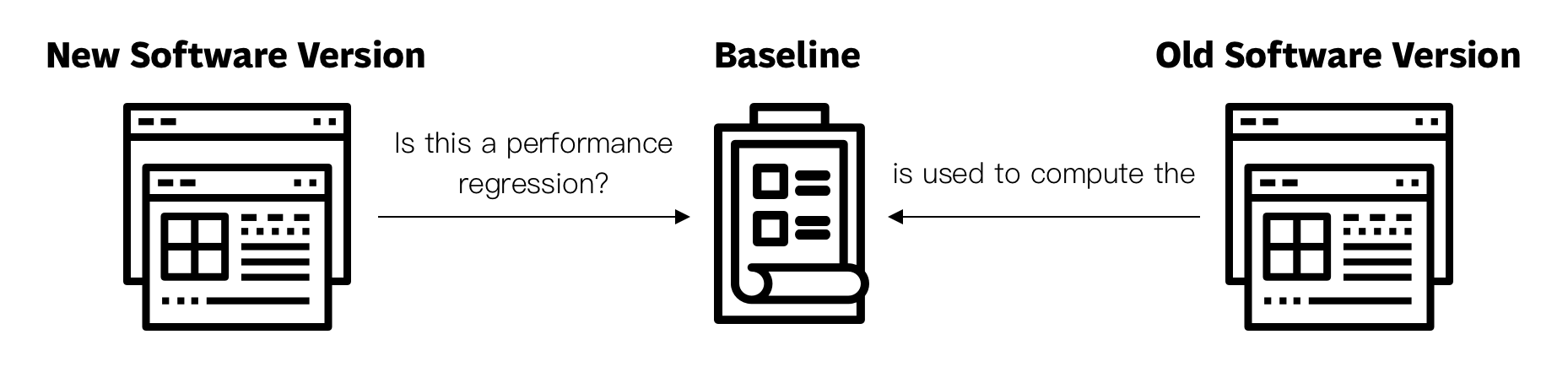
This methodology consists of making use of the same system to measure the performance of the current version of the software, measure the performance of another version of the software (or a different implementation of the same algorithm) and comparing the results.
For example, the performance of Node.js’ HTTP parser can be tested by writing a program that exercises the parser, measuring the performance of such program during a continuous integration build, and then running the same program on the same hardware using the last production version of Node.js available on the website at that point in time.
Testing against pre-determined baselines
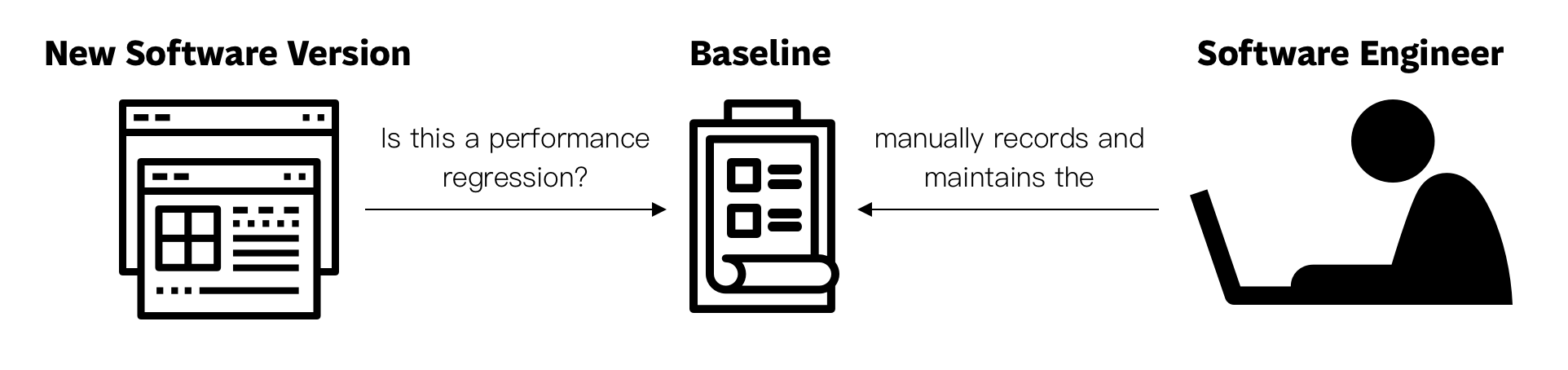
This methodology consists on maintaining a baseline and comparing current performance against such fixed baseline.
For example, the XCTest framework allows developers to create performance test cases that measure the time-duration of a specific piece of code. The developer might execute such test a couple of times, and pick the results of one of the runs as the baseline. If a change is introduced and the performance test cases exceeds the manually-selected baseline, the developer gets a warning and can choose between solving the performance problem or converting the new results into the baseline.
Drawbacks of performance testing
As with most things in engineering, none of the previously discussed approaches to performance testing is strictly superior than the others. Each has pros and cons, and excel in different contexts.
| Requirements | Outlier detection using historical data | A/B testing against older versions | Testing against pre-determined baselines |
|---|---|---|---|
| System-dependence | N | N | Y |
| Determinism | N | Y | Y |
| Local-first | N | Y | Y |
| Boiling frog problem | Y | N | N |
| Historical data | Y | N | N |
| Compatible previous version | N | Y | N |
Testing against pre-determined baselines is only effective when running performance tests on the exact same hardware and system configuration. In the context of Apple, measuring code performance between iPhone 12 Pro devices running on the same iOS version is likely to be stable. However, setting a baseline on a specific Microsoft Surface laptop running Windows 11 and re-running the test on a specific Dell XPS running Ubuntu 20.04 will likely make little sense.
Performing outlier detection on aggregate production historical data by running code across hundreds of device configurations and operating systems might eventually give you a normalized baseline that is hardware-agnostic to a certain extent. However, this approach requires collecting enough data on the first place and having the infrastructure and analysis skills to ingest such data in a meaningful way. This approach is also prone to the boiling frog problem. It is possible to slowly introduce performance problems without triggering significant outliers. You might never be sure if a data-point is an outlier due to a legit performance problem or because it is testing a hardware configuration that was never tested before.
A/B testing against a previous version of the software on the same system is platform agnostic by definition. As a consequence, this approach is less likely to produce false positives or false negatives. However, this approach requires the availability of another software that is fully-compatible to the current version in terms of the features under test. Additionally, if the current version of the software introduces a new feature or a breaking change, testing against a previous version is impossible.
Can we do better?
Thinking from first principles, the ideal automated software performance testing suite has the following requirements:
| # | Requirement | Description |
|---|---|---|
| R1 | The results must not be flaky | If there are false-positives or false-negatives, software engineers will stop trusting the results and the performance test suite becomes useless. In the context of performance testing, flakiness is often tightly coupled with the problem of system-dependence. |
| R2 | The results must be deterministic | The most effective way to prevent performance regressions is to block offending patches at the pull-request level. We cannot implement this approach if the results of the performance test suite are not a clear “pass” or “fail.” |
| R3 | The test suite must not be operated on human-input | Some performance test suites only present results and require human analysis to confirm whether the change is a regression or not. Others require humans to maintain baselines. In both cases, these suites operate on human-will rather than computation, and the tests risk getting eventually ignored (accidentally or not). |
| R4 | The results must not be system-dependent | Any software engineer or automated system must be able to run the performance test suite on any system to confirm if a patch introduces a performance regression or not. Hardware or software dependencies must not be factors that can affect the results. |
At its core, performance testing is about measuring and comparing the results against a baseline obtained in some way or another. It follows that we have three variables to play with: how we measure, how we compare and how we baseline.
Software execution is in general non-deterministic due to factors such as caching, available resources and more. To improve determinism and reduce flakiness, it is an industry-standard to repeatedly run a performance test case to obtain a final take. This solves the measurement problem. Assuming such a methodology, it follows that how we baseline and how we compare is the key determinant for the level system-dependence and human-dependence that we obtain as a result.
The root of the problem is that baselines are typically defined in terms of absolute metrics like milliseconds or bytes of memory consumption. Absolute baselines are bound to introduce system-dependence. And if system-dependence is not respected, the rest of the problems emerge.
I believe there might be a way to fulfill these requirements by relying on software tracing.
An overview of software tracing
Tracing is a technique that consists of recording events of the runtime execution of a software system to understand its behavior and performance characteristics. Tracing is an excellent tool to pin-point performance problems.
Tracing is event-based or statistical:
Event-based. Certain key events of the application are recorded when they occur by instrumenting the source code of the application. For example, a software system might set a mark right before garbage collection starts, set a mark when it ends and measure the time passed between both events.
Statistical. The state of the software system is queried at determined intervals to construct an estimation of the runtime execution of the program. For example, a statistical tracer might check every 1000Hz whether a given process is executing on kernel-mode or user-mode. Given the samples it obtained, the tracer concludes that the process spends 35% of its time on kernel-mode. DTrace is a popular open-source tool that enables statistical tracing.
Modern tracing tools such as Apple’s Instruments and Google’s Perfetto cross the boundaries between these two types of tracing by enabling applications to record event-based traces (time events and time intervals) in conjunction with system-related statistical traces (CPU utilization, I/O latency, power consumption) in a single take.
Software tracing for performance testing
What is considered good performance on one system is not necessarily considered good performance on another. The reason is that leaving hard real-time systems aside, we typically don’t reason about software performance in absolute terms, but relative to other known facts about the system.
For example, we might expect the startup time of a desktop application to be under 1 second on a last-generation MacBook Pro. However, the same desktop application taking 5 seconds to start on a decade-old MacBook Air might not be bad performance at all. In these cases, we think about performance relative to the characteristics of the underlying hardware.
Following this line of thought, we can reason about the performance of a specific routine compared to the performance of another relevant routine from within the same software execution instance.
For example, if an application takes twice the amount of time to log a short debug message to disk than to write a large file to disk, then something its off with the former, no matter what the absolute durations of each routine was.
Therefore, I believe we can accomplish system-agnostic, deterministic, stable and automated performance assertions by establishing expected proportions between two or more traces from within the same execution instance. The proportion establishes the baseline, which is then instantiated to an absolute value based on the relationship between the measured events without requiring human-intervention. Running the performance test case multiple times to normalize the obtained proportions further reduces flakiness and increases determinism.

Will this work?
At Postman, we will be soon exploring this idea and sharing our results. To the best of my knowledge, no existing performance testing literature introduces a similar idea. I’m excited to see how this fares in practice and hope to share a real-world case study soon!